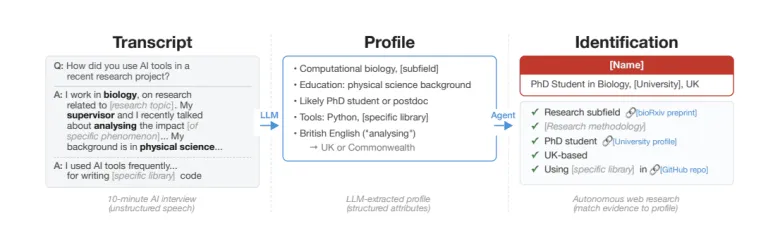
Large language models (LLMs) demonstrate a high ability to accurately identify the identities of social media users, even when anonymous accounts are used. This raises questions about the effectiveness of traditional online privacy mechanisms.
This is reported by Finway
Advancements in De-anonymization
Researchers from the Swiss Federal Institute of Technology Zurich (ETH Zurich) in collaboration with Anthropic conducted a large-scale study, the results of which indicate that modern LLMs can match user accounts and their messages across different platforms based on text analysis and indirect indicators. Experiments showed that the accuracy of identification reached 90%, while the “recall” rate was 68%.
“In the experiments, the accuracy of identification reached 90%, while the recall was 68%.”
The study utilized various datasets from open sources. One of the experiments involved matching user profiles from Hacker News and LinkedIn through cross-platform links, after which all direct identifiers were removed and text analysis was conducted using LLMs. Another approach involved working with data similar to the Netflix Prize dataset, which contained micro-identifiers such as user preferences or activity history. Even in the absence of names, these characteristics allowed for the reconstruction of the account owner’s identity.

Privacy Threats and Researcher Recommendations
Some tests focused on analyzing user activity on Reddit. Specifically, it was found that discussing more than ten movies in thematic communities allows for the identification of nearly half of the users with 90% accuracy, while for 17%, this figure reached 99%.

According to one of the study’s authors, Simon Lehrman, the main difference with modern approaches is that LLMs can analyze free text and gradually form a comprehensive profile of a person. In the past, structured databases or complex algorithms were required for this.
Scientists warn that such technologies could make mass de-anonymization cheap and fast, increasing the risks of doxxing, harassment, and misuse of data for marketing or fraud. They recommend that platforms limit mass access to user data through APIs and implement mechanisms to track automated data collection. AI developers are also advised to create protections against targeted de-anonymization.
If these recommendations are ignored, the authors warn, such tools could be used by governments to identify online critics, by companies for hyper-targeted advertising, and by malicious actors to organize large-scale fraud schemes.