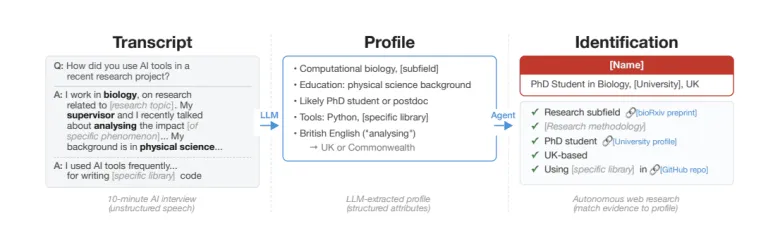
Великі мовні моделі (LLM) демонструють здатність з високою точністю ідентифікувати особистості користувачів соціальних мереж навіть у разі використання анонімних акаунтів. Це піднімає питання щодо ефективності традиційних механізмів конфіденційності в інтернеті.
Про це розповідає Finway
Досягнення у сфері деанонімізації
Дослідники зі Швейцарської вищої технічної школи Цюриха (ETH Zurich) спільно з компанією Anthropic провели масштабне дослідження, результати якого свідчать: сучасні LLM здатні зіставляти акаунти користувачів та їхні повідомлення на різних платформах, ґрунтуючись на аналізі тексту та непрямих ознак. Експерименти показали, що точність ідентифікації досягала 90%, а показник «повноти» — 68%.
“В експериментах точність ідентифікації сягала 90%, а повнота — 68%”.
У межах дослідження були використані різноманітні набори даних із відкритих джерел. Один із експериментів полягав у зіставленні профілів користувачів Hacker News та LinkedIn через міжплатформні посилання, після чого всі прямі ідентифікатори видалялися і відбувався аналіз тексту за допомогою LLM. Інший підхід включав роботу з даними, схожими на набір Netflix Prize, які містять мікроідентифікатори на зразок вподобань чи історії дій користувачів. Навіть за відсутності імен ці характеристики дозволяли відновити особистість власника акаунта.

Загрози для приватності та рекомендації дослідників
Окремі тести стосувалися аналізу активності користувачів Reddit. Зокрема, виявилось, що обговорення понад десяти фільмів у тематичних спільнотах дозволяє ідентифікувати майже половину користувачів з точністю до 90%, а для 17% — цей показник сягав 99%.

За словами одного з авторів дослідження, Саймона Лермана, головна відмінність сучасних підходів у тому, що LLM можуть аналізувати вільний текст та поступово формувати цілісний профіль особи. У минулому для цього були потрібні структуровані бази даних або складні алгоритми.
Науковці попереджають: подібні технології можуть зробити масову деанонімізацію дешевою та швидкою, а це підвищує ризики доксингу, переслідувань та зловживань даними для маркетингу чи шахрайства. Вони рекомендують платформам обмежувати масовий доступ до користувацьких даних через API та впроваджувати механізми відстеження автоматизованого збору інформації. Також розробникам ШІ радять створювати захист від цільової деанонімізації.
У разі ігнорування цих рекомендацій, застерігають автори, подібні інструменти можуть бути використані державами для виявлення онлайн-критиків, компаніями — для гіпертаргетованої реклами, а зловмисниками — для організації масштабних шахрайських схем.